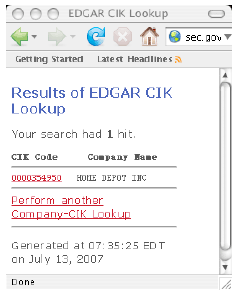
AbstractThis paper describes how use the HTMLEditorKit to perform web data mining on EDGAR (Electronic Data-Gathering, Analysis, and Retrieval system). EDGAR is the SEC's (U.S. Securities and Exchange Commission) means of automating the collection, validation, indexing, acceptance, and forwarding of submissions. Some entities are regulated by the SEC (e.g. publicly traded firms) and are required, by law, to file with the SEC. Our focus is on making use of EDGAR to get information about company offers to purchase stock, known as tender offers. These offers are filed with companies, using their Central Index Key (CIK). The CIK is used on the SEC's computer system to identify corporations and individual people who have filed a disclosure with the SEC. We show how to map a stock ticker symbol into a CIK and how to extract tender offer data. Our example show how we extract the number of shares tendered, the price range for the auction, the honoring of "odd lots" and the initial termination date for the auction. The methodology for converting the web data source into internal data structures is based on using HTML as input into a parser-call-back facility that builds up a data structure using a context sensitive table data. Screen scraping is a popular means of data entry, but the unstructured nature of HTML pages makes this a challenge.1 THE PROBLEMThe Williams Act (named for New Jersey Senator, Harrison A. Williams of New Jersey ) was passed into law in 1968. The act requires that a company who engages in a tender offer state all details of the offer in a filing to the SEC. The filing must include the terms, cash source, any plans for the company after takeover, etc. The law mandates a minimum offering period of 20 days and gives tendering shareholders 15 days to change their minds. If only a limited number of shares are accepted, they must be prorated among the tendering stockholders. Since 1996, all public domestic companies have been required to make their filings with the SEC using the EDGAR system (except in the case of hardship). Since 2002 this ruling has also applied to those foreign companies that are subject to regulation by the SEC. In short, most filings are electronic and these filings constitute a domain-limited financial narrative that is available on the web. According to our scanning program, there have been 6,842,333 filings made using the EDGAR system between Q1 of 1996 and 7/15/07. Of these, 2,828 are of type "SC TO-I" (primary tender offers). There were third-party tender offers, and amendments to tender offers, but we did not count these. The massive nature of the database makes automation of the mining process desirable. Thus, we are given an HTML data source, in EDGAR, and we would like to find a way to create an underlying data structure for describing tender offers that is both type-safe and well formulated. We are motivated to study these problems for a variety of reasons. Firstly, for the purpose of conducting empirical studies, entering the data into the computer by hand is both error-prone and tedious. We seek a means to get this data, using free data feeds, so that we can build dynamically updated displays and perform data mining functions. Secondly, we find that domain limited data should be easier to parse, yet it is surprisingly difficult and these challenges enable us to hone our techniques for data mining. This example is used in a first course on network programming. 2 FINDING THE DATAFinding the data, on-line, and free, is a necessary first step toward this type of data mining. We obtain EDGAR filings by using the SEC's CIK (Central Index Key). The keys are stored in a table that is available via anonymous FTP at ftp.sec.gov. The table is updated daily and is large. The keys are also available via a web interface lookup feature. The interface requires a company name (not a ticker symbol). However, we are used to entering ticker symbols and prefer that be used for the interface. Thus, our first step is to map the ticker symbol into a company name, then use the company name to query the CIK database. It is then a matter of constructing an HTML parser that is able to extract the CIK from the EDGAR reply. For example: http://www.sec.gov/cgi-bin/cik.pl.c?company=home+depot This creates an output on the screen that looks Figure 1-1.
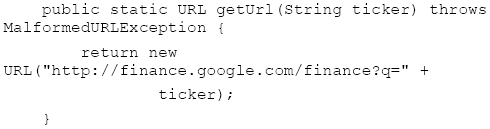
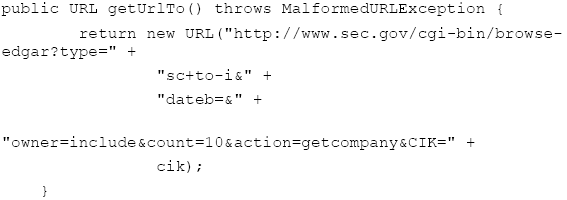
Figure 1-1. The EDGAR CIK To synthesize the URL needed to get the data, we use: Where: Is needed to make sure that illegal URL characters, like spaces, are replace with their decimal equivalents. After a great deal of development, we discover that the EDGAR system has bugs in its' query results. For example, a search for: "Dominion Resources Inc" results in: The first (and last company) is "DIGITAL IMAGING RESOURCES INC". The second and third companies represent a change of location. For example, Dominion is listed as: "formerly: DOMINION RESOURCES INC /TA/ /TA (filings through 2006-03-27))". Thus "getUrlCIK2" becomes the backup query engine, with the primary query formulated with: We automatically fall-back to the secondary source, in the case of primary source failure. 3 ANALYSISWe use a ParserCallBack class to process the HTML data. The goal is to identify the relevant data in the HTML responses from the primary and secondary sources. In the case of the primary source, we get: And in the case of the secondary source we get hrefs in the form of: Thus, we are interested in anchor tags that contain href attribute "CIK=". This is done with a combination of standard callback features and ad-hoc string manipulations. Each time we approach the problem of parsing new data, our goal is to make the parser tool a little bit more general (and thus reusable): We are using the ParserCallBack to look for the primary and secondary URLs: and: For example, on the secondary URL, the href attribute that is returned is: Thus it is a simple (though data-specific) matter to isolate the CIK string and parse it. The CIK is now a unique key into the EDGAR database and is stored in: We make use of the Google summary data because YAHOO finance tends to mangle the name of the company in its title. We obtain the Google summary in order to obtain the company name and then transform the name into a form that the Edgar system will recognize. The URL for Google finance is extracted from:
Figure 2-1. Sample Google output Figure 2-1 shows the title in the sample Google output. The SEC wants the commas and periods removed from the title, in order to recognize the query. It also wants a series of other changes to normalize the form of the company name. This logic was incorporated, in an ad-hoc string manipulation procedure, embedded in the setter of the GoogleData: For example, the Edgar system is confused by "The Home Depot, Inc.", it wants "Home Depot Inc". Also, "TLC Vision Corporation (USA)" must be "TLC Vision Corporation" and "Liberty Media Corporation" must be "Liberty Media Corporation". However, "Document Sciences Corporation "must be written as "Document Sciences Corp". Even more special cases are needed with the Edgar search engine when things don't work the first time, thus accounting for: 4 BUILDING THE INTERFACEWe are interested in a new "killer application" for development, called the JAddressBook program. This program is able to chart historic stock volumes (and manage an address book, dial the phone, print labels, do data-mining, etc.). The program can be run (as a web start application) from: http://show.docjava.com:8086/book/cgij/code/jnlp/addbk.JAddressBook.Main.jnlp
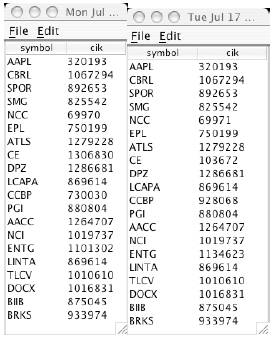
Figure 3-1. The Stock Symbols Dialog Figure 3-1 shows entry of stock symbols into the stock symbols dialog. Once the user selects "done" a table of Edgar CIK numbers is constructed.
Figure 3-1. The CIK table Figure 3-1 shows an image of the CIK table for a series of different symbols. CIK numbers can help to obtain information, not only from the query system, but also from the FTP file system that mirrors the Edgar filings. 5 MINING THE FTP SITEThere are a series of ftp files that are available on the Edgar site. They are text files that have been compressed, using GZIP. The database is too large to fit into RAM, however, it can be scanned, gradually. Since 1996, there were 6,842,333 electronic filings made to the EDGAR system. These are indexed in compressed text files. There are 4 files per year (one per quarter). The indexed files show the CIK number and the form type. The form type is coded according to a standard. For example, we are interested in tender offers, so we can scan for form type "SC TO-I". Since 1996 there were 2,828 "SC TO-I" filings on EDGAR. 6 QUERY EDGAR TENDER OFFER FILINGSIn the previous section, we showed how to use EDGAR to obtain CIK data on a stock, given its symbol. In this we, how to process EDGAR tender offer filings on a stock, given its symbol. Queries can be formulated without a CIK and typed directly into a browser. For example, for Home Depot, the CIK is 353950, thus: Will return an output, in the browser that looks list Figure 4-1.
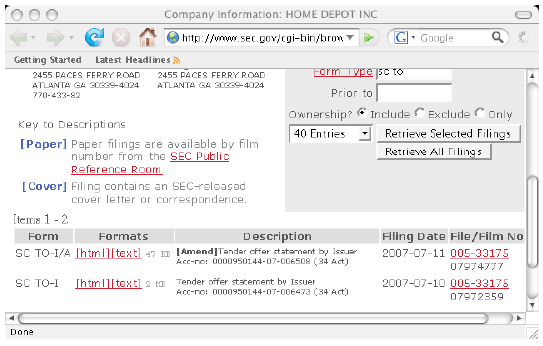
Figure 4-1. Tender Offer Filings with the SEC Our first step is to scan the document for links, reformulate the relative links so that they are absolute links, sort them and remove the duplicates. We formulate the tender offer URL using: And we can test our href link parser using: Where the heart of the links parser is given by: We selected to ignore the mailto and javascript based hrefs as these are not important to our application. The output follows (the CIK leads the way):
http://www.sec.gov/Archives/edgar/data/354950/000095014407006473/0000950144-07-006473-index.htm http://www.sec.gov/Archives/edgar/data/354950/000095014407006473/0000950144-07-006473.txt http://www.sec.gov/Archives/edgar/data/354950/000095014407006508/0000950144-07-006508-index.htm http://www.sec.gov/Archives/edgar/data/354950/000095014407006508/0000950144-07-006508.txt http://www.sec.gov/cgi-bin/browse-edgar?action=getcompany&CIK=0000354950&owner=include&count=10 http://www.sec.gov/cgi-bin/browse-edgar?action=getcompany&SIC=5211&owner=include&count=10 http://www.sec.gov/cgi-bin/browse-edgar?action=getcompany&State=GA&owner=include&count=10 http://www.sec.gov/cgi-bin/browse-edgar?action=getcompany&filenum=005-33175&owner=include&count=10 http://www.sec.gov/cgi-bin/browse-edgar?action=getcurrent http://www.sec.gov/edgar/searchedgar/webusers.htm http://www.sec.gov/info/edgar/forms/edgform.pdf http://www.sec.gov/info/edgar/ofis.shtml#access Since we are only interested in the links to tender offers, we isolate the hrefs that end with.txt : http://www.sec.gov/Archives/edgar/data/354950/000095014407006473/0000950144-07-006473.txt http://www.sec.gov/Archives/edgar/data/354950/000095014407006508/0000950144-07-006508.txt 7 PARSING TENDER OFFERSThe previous section shows how to obtain all the relevant links that the SEC has in Edgar for tender offers. The next bit is a tad tricky. The first step is to construct the target data structure of the parsing operation: In a Dutch tender offer, managers select a price range for tendering and announce the number of shares to be repurchased, the termination date of the offer and whether or not the odd-lot rule is in effect. Where an odd lot is defined as a number of shares that is less than 100. When the "odd lot rule" is in effect, the company will purchase any lot of shares less than 100, without proration. Proration occurs when more stock is tendered than the company is authorized to purchase. Using Edgar filings on tender offers is surprisingly difficult. There are no standards for the statement and there is a good deal of variation from one statement to the next. Still, using ad-hoc string manipulation techniques, we were able to derive the following information from the Edgar database: The high-level API for doing this makes the job looks easy and reliable. It is neither. The heart of the parser is given by: We obtain the contents of the URL as one large string, convert it to upper case, strip out the control characters and some of the HTML tags. We then set to work with ad-hoc string manipulations: Where the simplified currency pattern is given by: For the termination date of the auction, we use: The isolate method strips off the prefix and the postfix string from the source, leaving a smaller, string of interest: 8 CONCLUSIONIn this paper we disclosed techniques that make use of the HTMLEditorKit and ad-hoc parsing to extract numeric, context-sensitive table data, from the web. This technique presents some reusable code, along with a plug-in style callback-parsing framework that is sensitive to changes in URL protocol and presentation data. A new set of problems appears when attempting to parse unstructured financial narratives (even in a domain restricted area). The question of how to best approach this problem remains open. After a Dutch auction is over, we should be able to mine the results and summarize them in a semi-automatic manner. This remains a topic of current research. Inconsistency in the wording of the company filings, along with inconsistency of the search results provided by the Edgar system conspired to make data mining a difficult task. REFERENCES[Lyon 04D] Java for Programmers, by Douglas A. Lyon, Prentice Hall, Englewood Cliffs, NJ, 2004. [Lyon 08C] "Multi-threaded Data Mining of EDGAR CIKs (Central Index Keys) from Ticker Symbols", by Douglas A. Lyon, 1st International Workshop on Parallel and Distributed Computing in Finance (PDCoF) 2008 Technical Program Friday April 18, 2008, Proceedings 22nd IEEE International Parallel and Distributed Processing Symposium. About the author
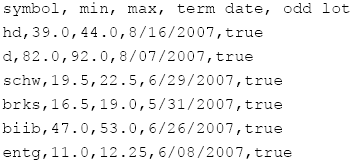
Douglas A. Lyon "Mining Edgar Tender Offers", in Journal of Object Technology, vol. 7. no. 7, September-October 2008 pp. 17-31 http://www.jot.fm/issues/issue_2008_09/column2/ |
|||||