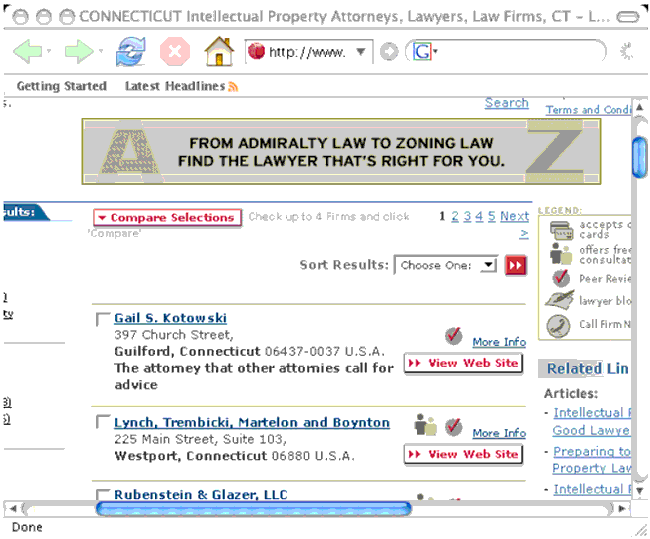
AbstractThis paper describes how to use web-based data mining to populate a flat-file database called the JAddressBook. The JAddressBook represents a next-generation address book program that is able to use web-based data mining. As it is also able to print mailing labels, and even initiate phone calls, it is useful for marketing. More over, its introduction to data mining has educational value, for those new to network programming, in Java. The methodology for converting the web data source into internal data structures is based on using HTML as input (called screen scraping). We explore a variety of techniques for reading the HTML data, as input. Our example focuses on mining data for lawyers.1 THE PROBLEMWeb-based data is generally available in an HTML format. Given a web-based source of an HTML formatted database, we would like to find a way to create an underlying data structure that is type-safe and well formulated, in response to a given query. Basically, we want POJOs (Plain Old Java Objects), extracted from HTML. The motivation for studying this type of problem ranges from the educational to the compelling next-generation killer applications (e.g., a 3 rd generation address book). The web is a source of data that is probably here to stay. It is almost certainly the largest source of data, as well as the fastest growing. Considering the general lack of the adoption of standards for the presentation of the data (particularly by those who would prefer not to share the data), we would like to take the data in an unstructured format and populate our data structures. Once we have the data, in our own database, we are at liberty to make use of it for a variety of applications. We will show an application that is able to print mailing labels from the addresses, for the purpose of marketing. We find students in our network programming classes are interested in data mining and that using real-world sources of data encourages students to become very creative in their approach to parsing the data. 2 FINDING THE DATAFinding freely available data, on-line, is a necessary first step toward this type of data mining. Databases of lawyers are available from a web site called lawyers.com. The URL that can obtain a list of intellectual property attorneys in the state of Connecticut looks like: http://www.lawyers.com/Intellectual-Property/CONNECTICUT/All-Cities/law-firms-p1.html?searchtype=Q This creates an output on the screen that looks like:
The output shown in Figure 2-1 is typical of the type of output encountered on the web. There are all manner of distracting artifacts on the page. Javascript, advertisements, side articles, unrelated buttons, etc. Most disconcerting is the lack of any indication of the number of records or number of pages needed in order to obtain the entire result set from the query. That is, by clicking on the Next button, we get to scroll to an entire new page of results from our query, but we don't know how many times we need to click Next in order to exhaust the result set. We break the problem into two sub-parts. The first is the creation of a URL for obtaining data; the second is the analysis of the results. To synthesize the URL needed to get the data, we use: There are three parameters used to create this URL, the lawyerType and stateName come from lists that are presented to the user via a dialog box. In order to fetch the data, given the URL, we write a simple helper utility that contains: The heart of the program is html2text, and this is covered in the following section. 3 ANALYSISHtml2text converts the HTML referenced by the URL into text, stripping out JavaScript, HTML, etc. and leaving one large text string that can be used for the purpose of data mining. There are many approaches to writing such a program (and we have tried a few of them): The EditorKit in Swing makes use of the inversion-of-control design pattern [GoF]. Inversion-of-control is a means by which a callback method is supplied in order to write a component that can be used in a larger framework. Basically, a class called TagStripper is used to remove the HTML tags found in the document. The removal is done by a series of handlers that are invoked when HTML tags are encountered: The tags of interest include TD (Table Data), Strong, B (Bold), and BR (line break). We assume that table data signifies a new record, and so insert the <newRecord> tag in order to ease parsing, downstream. The other tags are used to denote fields within the record. Processing data, using an HTMLEditorKit, makes data mining of text data a little easier enabling us to work at a higher level. The output looks like: In order to determine how many results are available, we can inspect the HTML output of a query. For example:
This indicates that there are 1,111 records in the result set. Also, from inspection of the web page, we conclude that there may be up to 25 records per page. Thus, we require 45 queries (1,111/25) in order to screen scrape the results. The ad-hoc nature of the parsing scheme is even more evident when we examine the string manipulations needed to obtain low-level data types: The use of the regexp "([0-9]+).+ listings" introduces a more powerful string matching tool than the low-level string processing (e.g. indexOf or StringTokenizer ). "[ ]" matches a single character that is contained within the brackets. For example, [012] matches "0", "1", or "2". "[0-9]" matches any digit. The plus sign indicates that there is at least 1 of the previous expression. "." Matches any single character. Thus we are searching for a string of digits followed by any character followed by the word "listings". Once we know how many records there are and how many pages there are, we write a loop to process the data; From a human interface point-of-view, data mining is a time-consuming operation, so it is good practice to provide a progress dialog box (with a cancel button) to keep the user updated about the state of the search. That is why we pass the progress dialog into the process method. The AddressDataBase is obtained from a singleton-pattern class that is used as a flat-file storage facility for our result set. What follows is an ad-hoc parsing scheme, using StringTokenizer to detect new lines and regular expressions to parse address records: The heart of the parser is in the regexp: Pattern pattern = Pattern.compile(".*,.*,.*,.*[0-9]{5}.*<newRecord>"); The only new feature is "[0-9]{5}.*<newRecord>" which says that we are looking for exactly 5 digits, followed by any number of characters, followed by "<newRecord>". The assumption is that 5 digits at the end of a record must be a zip code (9 digits with a hyphen will work too). This is a critical assumption. Should the suppler alter the format of the data, this code will break (and has done so in the past). The question of how to make this type of processing more robust remains open. To obtain the AddressRecord we proceed to use an ad-hoc application of a StringTokenizer : The AddressRecord contains the name, address, information and some phone numbers: For the purpose of this type of this application, phone numbers are not present in the data, and so this area of the record is left blank. 4 DISPLAYWe are interested in a new "killer application" for development, called the JAddressBook program. This program is able to display stock quotes (and manage an address book, dial the phone, print labels, do data-mining, etc.). The program can be run (as a web start application) from: http://show.docjava.com:8086/book/cgij/code/jnlp/addbk.JAddressBook.Main.jnlp And provides an interactive GUI for data mining addresses.
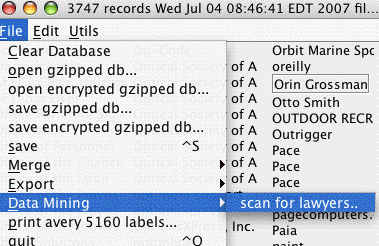
Figure 4-1. The Scanning for lawyers Figure 4-1 shows an image of the data mining addressbook. Users are asked to select a state from a standard list of states (using two-letter postal codes):
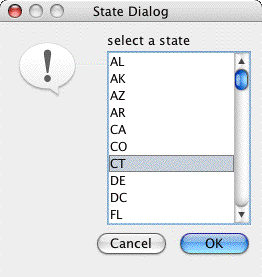
Figure 4-2. State Selection Dialog Figure 4-2 shows an image of the state selection dialog.
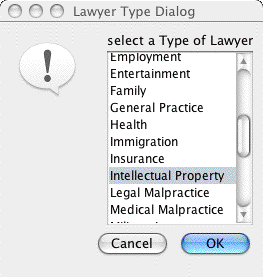
Figure 4-3. The Lawyer Type Dialog Figure 4-3 shows an image of the lawyer type dialog.
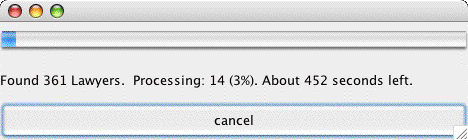
Figure 4-4. The Progress Dialog The progress dialog is updated, dynamically, in order to provide feedback to the user. Considering the amount of time it takes (several minutes is not that unusual) a multi-threaded feedback mechanism improves the usability of the application. 5 IMPLEMENTING AN ADDRESSBOOKIn order to provide a consistent rendering of the address book database, the singleton design pattern is used. The class is made final, so that it cannot be sub-classed. The constructor is left private, so that the class cannot be instanced by other classes: The database is stored in a compressed serialized gzipped file. If the file name cannot be retrieved, the database is initialized with a single blank record. Databases can be stored in a variety of different formats (XML, CSV, etc.). Also, data can be merged from a variety of different formats. 6 RESOURCE BUNDLINGThe file name is stored in the users' preferences, as described in described in [ Lyon 05A]. This enables the program to remember where the last database file was held. By making use of the user preferences in this way, the location of the database file is user-root specific. This means that different users will get different files when they make use of different accounts: Serialization of the entire address book to the user root preferences is not possible (due to size limits). However, the preferences can easily handle a file name. Should that file name become corrupt, the opening of a new file (from the file menu ) will reset the location of the most recently used file. 7 CONCLUSIONWe showed how an EditorKit, regular expression and StringTokenizers were combined using ad-hoc parsing techniques to obtain data from the web. Variation in data format on the web remains a topic of concern for the robustness of this class of programs. As we proceed to attack more sophisticated data mining tasks we refine our toolkit. Thus, we are still learning by experimenting with new sources of data. The web represents a hodge-podge of data sources and parsing is proving to be a hard task (though very worth-while!). The more general the data format that we attempt to attack; the more sophisticated our tools become. Our program has broken at least once before (as the source of the data changed format). The question of how to deal with changing data formats remains open. A generalized means of providing some kind of meta-data description that gives semantic meaning to HTML documents is needed. HTML tags serve as important landmarks when performing this type of language processing. The most general approach might convert HTML into XML, with specific semantic tags. The question of how this is implemented remains open. REFERENCES[ Lyon 05A] "Resource Bundling for Distributed Computing," by Douglas A. Lyon, Journal of Object Technology, vol. 4, no. 1, January-February 2005, pp. 45-58. http://www.jot.fm/issues/issue_2005_01/column4/ [GoF] Erich Gamma, Richard Helm, Ralph Johnson, and John Vlissides, Design Patterns: Elements of Reusable Object-Oriented Software, Reading, MA, Addison-Wesley, 1995. About the author
Cite this column as follows: Douglas A. Lyon "Data Mining Address Book", in Journal of Object Technology, vol. 7. no. 1, January - February 2008 pp. 15-26 http://www.jot.fm/issues/issue_2008_01/column2/ |
|||||