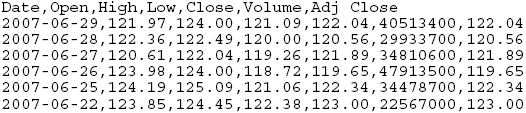
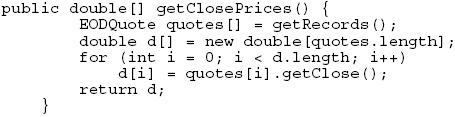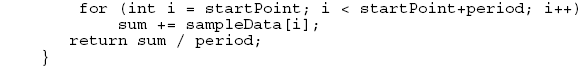AbstractThis paper describes how to extract historic stock quote data and display it. We show how to chart stock prices, using the web as a data source. The methodology for converting the web data source into internal data structures is based on using HTML as input. This type of screen scraping has become a popular means of recording data into programs. Simple string manipulation techniques are shown to be good enough for these types of well-formed data streams. 1 THE PROBLEMHistoric stock price data is generally available on the web (using a browser to format the HTML data). Given an HTML data source, we would like to find a way to create an underlying data structure that is type-safe and well formulated. We are motivated to study these problems for a variety of reasons. Firstly, for the purpose of conducting empirical studies, entering the data into the computer by hand is both error-prone and tedious. We seek a means to get this data, using free data feeds, so that we can build dynamically updated displays and perform data mining functions. Secondly, we find that easy to parse data enables us to teach our students the basic concepts of data mining. This example is used in a first course in network programming. 2 FINDING THE DATAFinding the data, on-line, and free, is a necessary first step toward this type of data mining. Quotes have been available, for years, from Yahoo. We can obtain the quotes, using comma-separated values (CSV) by constructing a URL and entering it into a browser. For example: http://table.finance.yahoo.com/table.csv?s=IBM&a=00&b=2&c=1800&d=04&e=8&f=2005&g=v&ignore=.csv This creates an output on the screen that looks like: Thus, we are able to obtain a listing of all the dividends that IBM paid, between two given dates. As another example, consider the week leading up to the IPhone release from Apple: http://ichart.finance.yahoo.com/table.csv?s=aapl&a=5&b=22&c=2007&d=5&e=29&f=2007&g=d&ignore=.csv The quotes are returned in the form: The URL is decoded as:
To synthesize the URL needed to get the data, we use: In order to fetch the data, given the URL, we write a simple helper utility that returns CSV data: The goal of such a program is to convert the URL into text, with one string per line, as retrieved from the web page. This is the core of the data retrieval phase. 3 ANALYSISIn order to process the CSV data we need to decide how we are going to store and parse the data. To store the end-of-day quote we create an EODQuote class, with appropriate getters and setters: To store multiple quotes, we create a container class that has high-level quote processing methods: Now if we want to get the close prices, we can use: Note that the symbol does not appear in either the EODQuote or in the EODQuotes. Our assumption is that the quotes in the quote container are homogeneous in the sense that they all come from the same stock. If this is not the case, the data processing that results will be hard to interpret (or worse). At this point, we build a mechanism for processing the data. For example, here is a simple moving average, with a period, measured in samples (in this case, trading days): Where the average for a single window is given by: 4 DISPLAYIn order to display our data, we use a graphing framework (whose description is beyond the scope of this paper; We are interested in a new "killer application" for development, called the JAddressBook program. This program is able to chart historic stock quotes (and manage an address book, dial the phone, print labels, do data-mining, etc.). The program can be run (as a web start application) from:
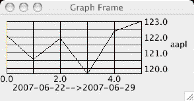
And provides an interactive GUI for charting stock data.
Figure 4-1. The Stock Chart Figure 4-1 shows an image of the chart. The mining of CSV data is not new, our approach to graphing stock data in Java may be [ Lyon 04D]. 5 IMPLEMENTING A STOCK CHARTThe stock chart is created using a graphing framework that makes use of the façade design pattern to simplify the interface: This program prints the following on the console: 6 CONCLUSIONThe number of options involved in graphing data is responsible for creating large and complex frameworks. Our example provides a means of formatting the start and end dates in accordance with the ISO8601 standard, and we have made use of this standard for the display of the data. The question of how to best get symbol and date data from the user remains open. For our example, we simply prompt the user for a string and leave the detail of creating complex looking calendar dialogs for another time. We showed how an ad-hoc parsing technique can be used to obtain CSV data from the web. The web is a huge and growing source of data. We rely upon others to keep the URL protocol and data consistent. So far, Yahoo is a reliable and free source of historic stock data. Decoding the URL is often a challenge, and, in particular, the historic stock data has many retrieval options. There are many sources of financial data in CSV format on the web. The question of what new uses we will find for this data remains open. REFERENCES[[Lyon 04D] Java for Programmers, by Douglas A. Lyon, Prentice Hall, Englewood Cliffs, NJ, 2004. About the author
Cite this column as follows: Douglas A. Lyon "Data Mining Historic Stock Quotes in Java", in Journal of Object Technology, vol. 6. no. 10, November-December 2007, pp. 17-23 http://www.jot.fm/issues/issue_2007_11/column2/ |
||||||||||